

L’apprentissage supervisé (en anglais : Supervised Learning) est le paradigme d’apprentissage le plus populaire en Machine Learning et en Deep Learning. Comme son nom l’indique, cela consiste à superviser l’apprentissage de la machine en lui montrant des exemples (des données) de la tâche qu’elle doit réalisée. Les applications sont nombreuses : Reconnaissance vocale, vision par ordinateur, régressions, classifications… La grande majorité des problèmes de Machine Learning et de Deep Learning utilisent l’apprentissage supervisé. Il est donc essentiel de bien comprendre le fonctionnement de cette mécanique.
Comment fonctionne l’apprentissage supervisé ?
Avec l’apprentissage supervisé, la machine peut apprendre à faire une certaine tâche en étudiant des exemples de cette tâche. Par exemple, elle peut apprendre à reconnaître une photo de chien après qu’on lui ait montré des millions de photos de chiens. Ou bien, elle peut apprendre à traduire le français en chinois après avoir vu des millions d’exemples de traduction français-chinois.
D’une manière générale, la machine peut apprendre une relation f : x \rightarrow y qui relie x à y en ayant analysé des millions d’exemples d’associations x \rightarrow y.
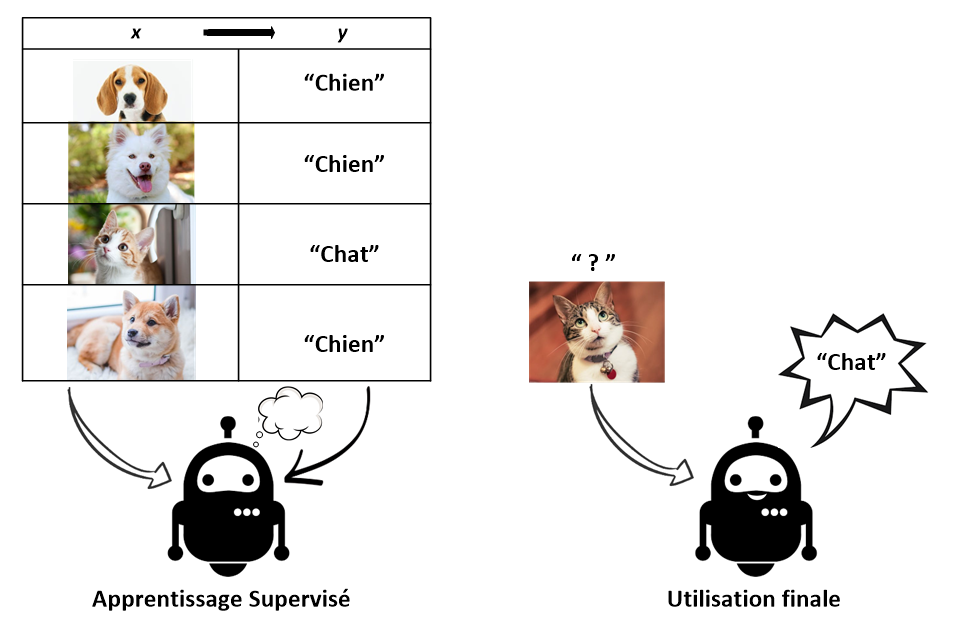
L’apprentissage supervisé fonctionne en 4 étapes :
- Importer un Dataset (x, y) qui contient nos exemples
- Développer un Modèle aux paramètres aléatoires
- Développer une Fonction Coût qui mesure les erreurs entre le modèle et le Dataset
- Développer un Algorithme d’apprentissage pour trouver les paramètres du modèle qui minimisent la Fonction Coût
Le Dataset : les exemples de ce qu’il faut apprendre
La première étape d’un algorithme de Supervised Learning consiste donc à importer un Dataset qui contient les exemples que la machine doit étudier.
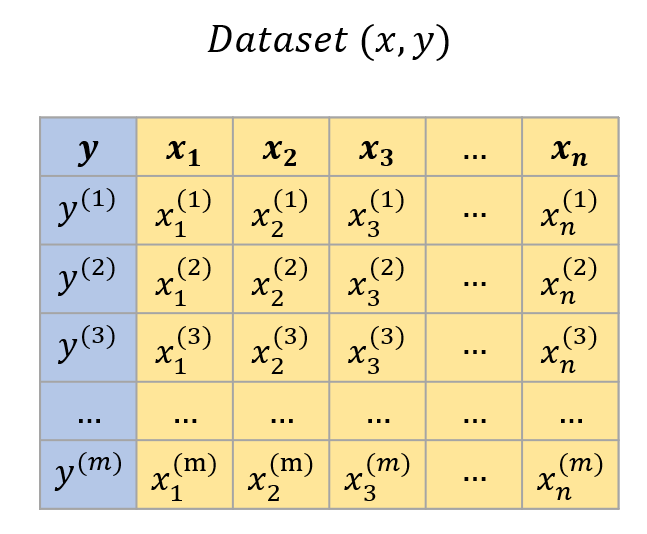
Ce Dataset inclut toujours 2 types de variables :
- Une variable objectif (target) y
- Une ou plusieurs variables caractéristiques (features) X
Par exemple, imaginez que vous visitez une série d’appartements un samedi après-midi. Pour chaque appartement, vous notez dans un tableau Excel le prix y et les caractéristiques X de l’appartement (la surface, la qualité, ville, etc.)
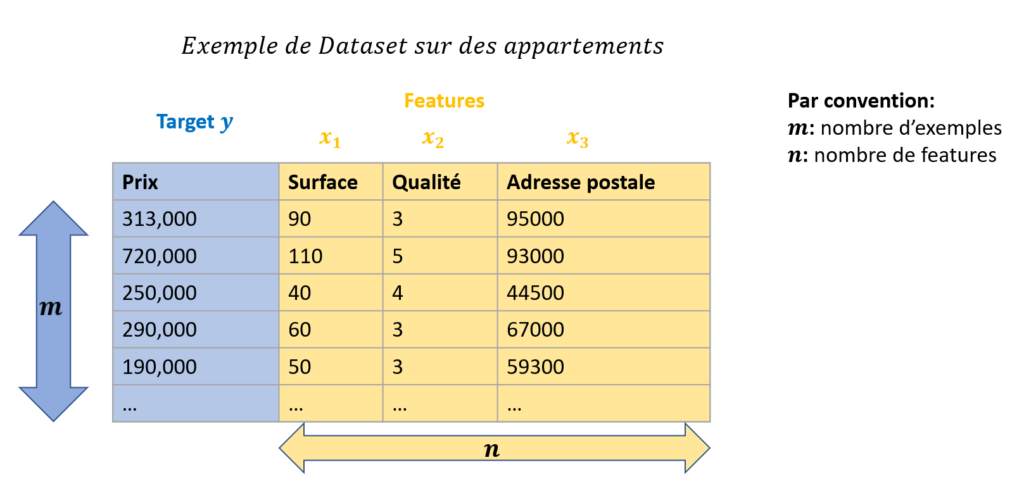
Par convention, on dit que notre Dataset contient m exemples, c’est-à-dire m lignes. Si vous avez visité 6 appartements, alors m=6.
Par convention, on note également n le nombre de features dans notre Dataset, c’est-à-dire le nombre de colonnes (hormis la colonne y). Si vous avez noté 3 caractéristiques pour vos appartement (Surface, qualité, ville), alors n=3.
Quand on développe un programme de vision par ordinateur, les features de notre Dataset peuvent être les pixels présents sur l’image. Un Dataset d’images de 8×8 pixels donne donc 64 features (n=64). Chacune de ces features correspondra à la valeur du pixel (un pixel noir = 1, un pixel blanc = 0)
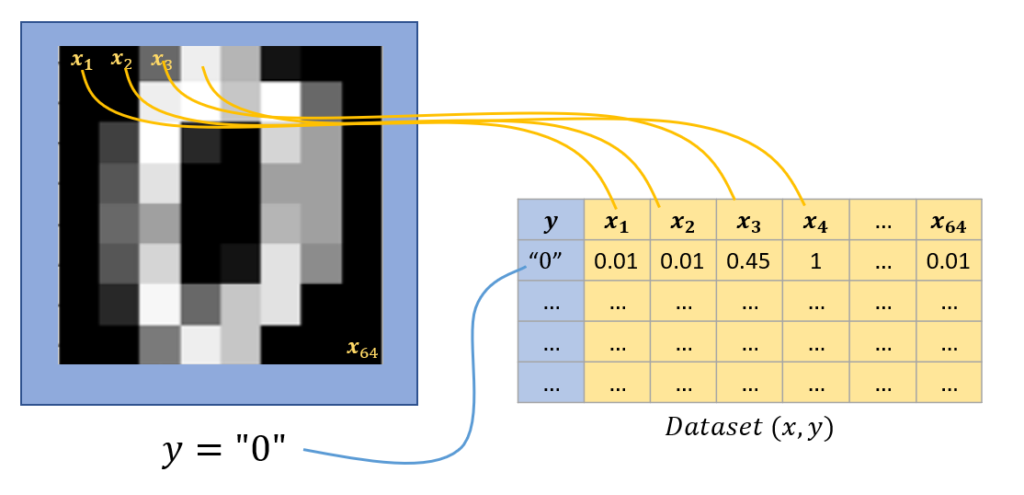
Dernière convention : pour désigner une cellule de notre tableau, on note en général x^{(ligne)}_{colonne}, c’est-à-dire que pour désigner la qualité du 3ième appartement que vous avez visité, on écrit x^{(3)}_2
Avec un tel Dataset, il devient possible de prédire de nouvelles valeurs y à partir de valeurs de x en développant un modèle, et c’est là notre 2ième étape dans la résolution d’un problème de Supervised Learning !
Le modèle : le cœur de votre programme
Le modèle est en quelque sorte le cœur de votre programme, c’est lui qui va effectuer la tâche que vous cherchez à accomplir, par exemple reconnaître un animal sur une photo ou prédire le prix d’un appartement.
Qu’est ce qu’un modèle ?
Pour rappel, un modèle est une représentation simplifiée de la réalité, que l’on peut utiliser pour prédire ce qui se passerait dans certaines conditions. Ça peut être un dessin, une équation physique, une fonction mathématique, une courbe… bref, n’importe quelle représentation.
Par exemple, si je lâche une pomme de 100 g depuis une hauteur de 4 mètres, en combien de temps tombera t’elle sur la tête de ce bon vieux Newton ? On peut prédire cela avec les équations de Newton. Dans ce cas, notre modèle est déterministe : il donnera toujours la même réponse sous les mêmes conditions.
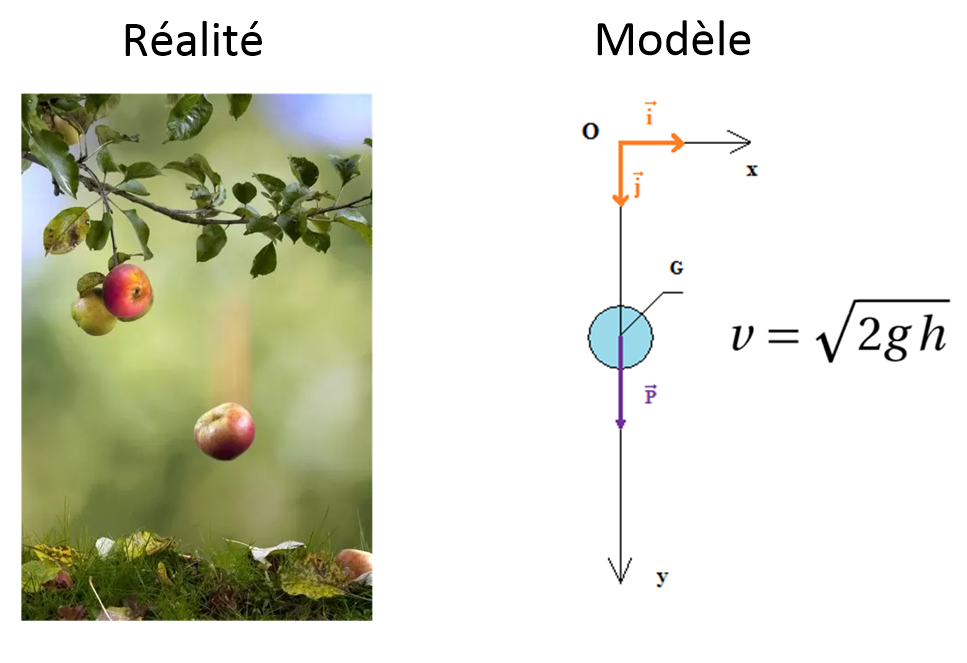
Mais pour prédire le prix d’un appartement en fonction de toutes ses caractéristiques, quelle est l’équation mathématique à entrer dans la machine ? Et quelle est l’équation pour reconnaître un chat sur une photo ? Nul ne le sait !
La solution ? Laisser la machine trouver le modèle qui correspond le mieux à votre Dataset (x, y) : c’est l’apprentissage supervisé.
Les modèles de Machine Learning
A la différence du modèle illustré plus haut, un modèle de Machine Learning ne repose pas sur une démonstrations mathématique ou une équation physique. A la place, il est construit à partir de données, comme un modèle statistique.
Si par exemple votre Dataset vous donne le nuage de point suivant, alors la machine devra trouver le modèle qui rentre le mieux dans ce nuage de point.
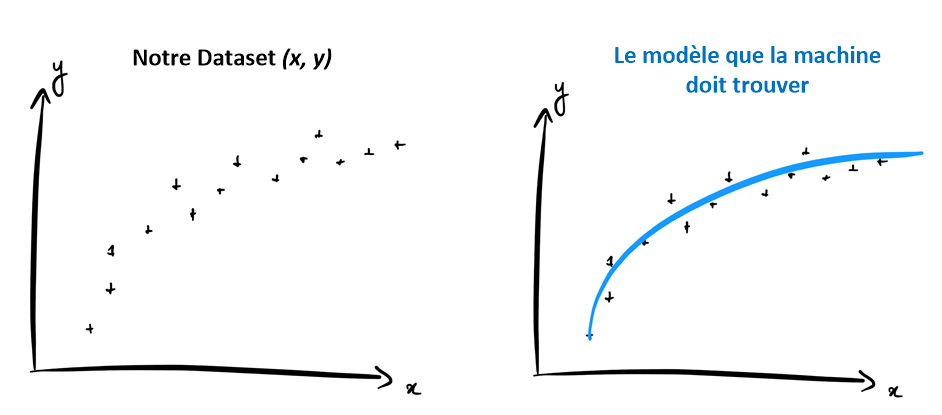
Cependant, ce n’est pas à la machine de faire tout le travail !
Dans les faits, c’est à nous de choisir le type de modèle (c’est-à-dire la fonction mathématique) et c’est à la machine de trouver les coefficients de cette fonction qui donnent les meilleurs résultats. Par convention on appelle ces coefficients les paramètres du modèle.
Par exemple, on peut choisir de développer un modèle linéaire f(x) = ax + b et on laisse la machine trouver la valeur de (a, b) qui donne les meilleurs résultats.
Ou bien on peut choisir un modèle non-linéaire, par exemple f(x) = ax^2 + bx + c, où (a, b, c) sont les paramètres. Les possibilités sont infinies, mais nous verrons plus tard dans cette formation comment choisir un modèle plutôt qu’un autre.
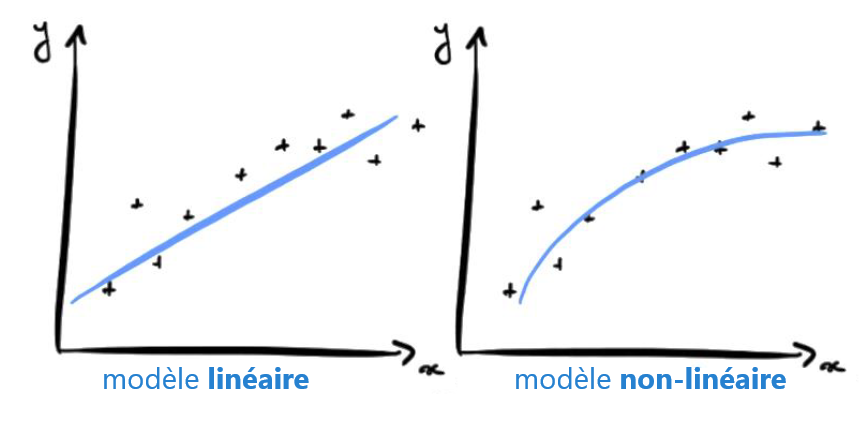
Maintenant, la question est : comment faire pour que la machine trouve le meilleur modèle ? Autrement dit, comment faire pour que la machine apprenne ?
La réponse est dans les étapes 3 et 4 !
La Fonction coût : mesure de la performance
Pour que la machine trouve le meilleur modèle, il faut déjà qu’elle puisse mesurer la performance d’un modèle donné. Vous ne me croyez pas ?
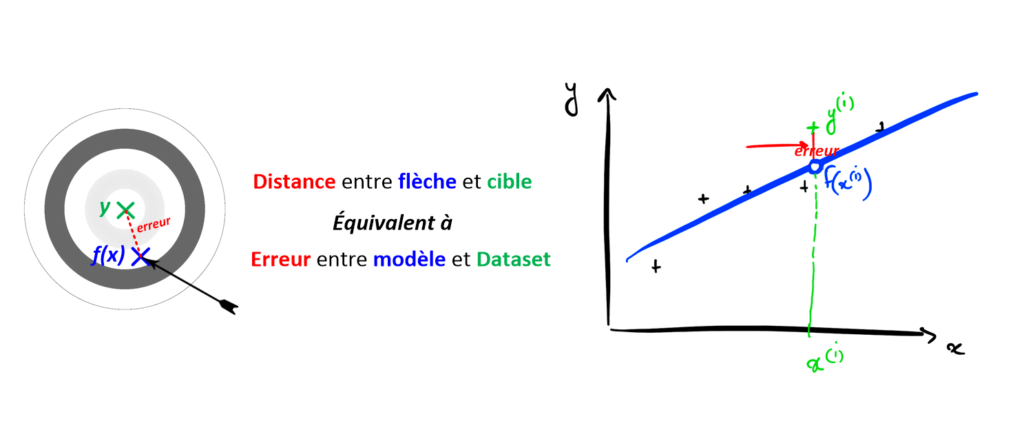
Imaginez que vous participiez à un concours de tir à l’arc. Comment savoir si vous êtes meilleur que votre voisin sans mesurer la distance entre vos flèches et le centre de la cible ? C’est impossible. Vous DEVEZ mesurer vos performances pour juger lequel de vous deux est le meilleur.
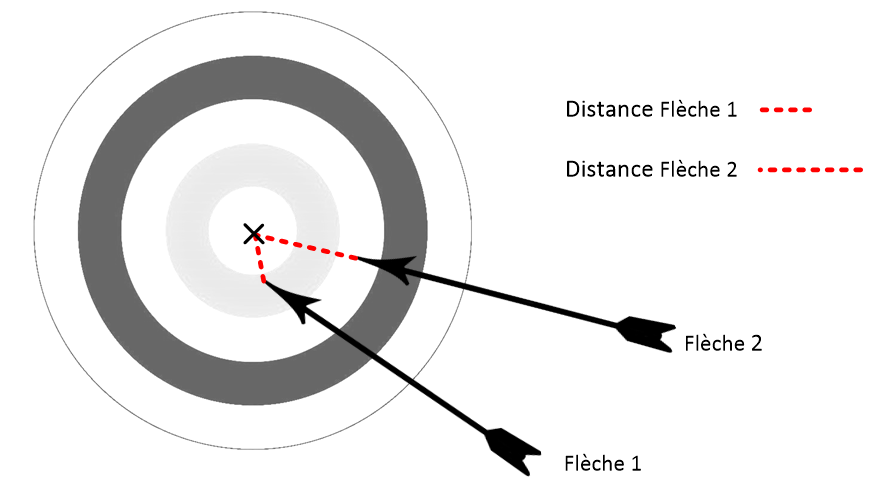
C’est la même chose en Machine Learning. Pour savoir quel modèle est le meilleur parmi 2 candidats, il faut les évaluer. Pour cela, on mesure l’erreur entre un modèle et le Dataset, et on appelle ça la Fonction Coût.
Dans le cas d’une régression, on peut par exemple mesurer l’erreur entre la prédiction du modèlef(x^{(i)}) et la valeur y^{(i)} qui est associée à ce x^{(i)} dans notre Dataset. C’est similaire à l’idée de mesurer la distance entre votre flèche (f(x^{(i)}) et le centre de la cible, qui n’est autre que le point (y^{(i)}) qu’elle est sensée atteindre.
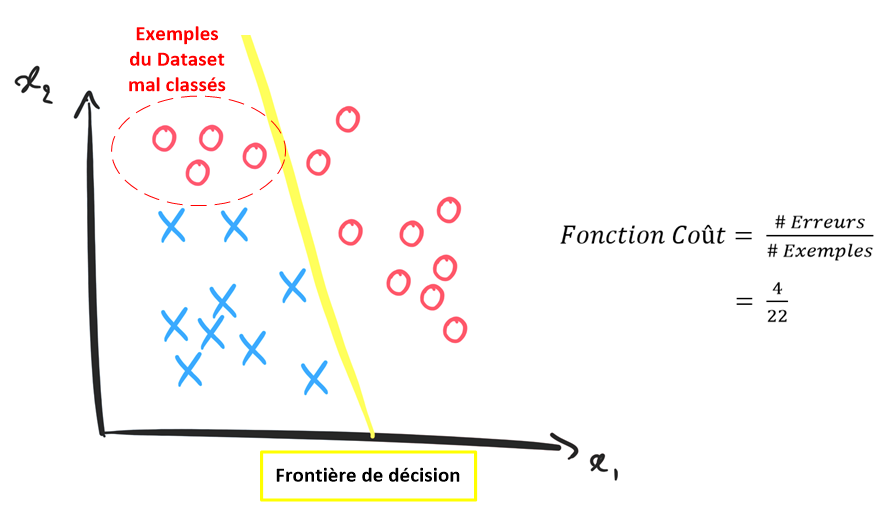
Maintenant, dans le cas d’une classification, on peut construire notre Fonction Coût en mesurant le nombre d’exemples du Dataset que notre modèle aura mal classé avec sa frontière de décision
Il existe beaucoup de métriques pour mesurer nos erreurs (MSE, MAE, RMSE, etc.) et nous verrons déjà l’un d’entre eux dans le prochain article de cette formation, ce qui vous permettra de passer au concret avec cette histoire de Fonction Coût.
Voilà pour l’étape 3 de notre problème d’apprentissage supervisé. A ce stade nous avons :
- Un Dataset
- Un Modèle
- Une Fonction Coût qui mesure les erreurs entre le modèle et le Dataset
Il est temps de passer à l’étape la plus importante en Machine Learning, celle qui donne vie à notre programme, l’étape d’apprentissage.
L’Algorithme d’apprentissage
Parlons peu, parlons bien. Avoir un bon modèle, c’est avoir un modèle qui de petites erreurs. Logique ?
Ainsi, en Supervised Learning, la machine cherche les paramètres de modèle qui minimisent la Fonction Coût. C’est ça qu’on appelle l’apprentissage. Cette phrase est très importante. C’est l’essentiel de ce qu’il faut comprendre en Machine Learning.
Pour trouver les paramètres qui minimisent la fonction Coût, il existe un paquet de stratégies.
On pourrait par exemple développer un algorithme qui tente au hasard plusieurs combinaisons de paramètres, et qui retient la combinaison avec la Fonction Cout la plus faible. C’est un peu comme organiser un concours d’archers pour ne garder que le meilleur. Cette stratégie est cependant assez inefficace la plupart du temps.
Une autre stratégie, très populaire en Machine Learning, est de considérer la Fonction Coût comme une fonction convexe, c’est-à-dire une fonction qui n’a qu’un seul minimum, et de chercher ce minimum avec un algorithme de minimisation appelé Gradient Descent. Nous le verrons en détails dans les prochains articles. Cette stratégie apprend de façon graduelle, et assure de converger vers le minimum de la fonction Coût (si convexe).
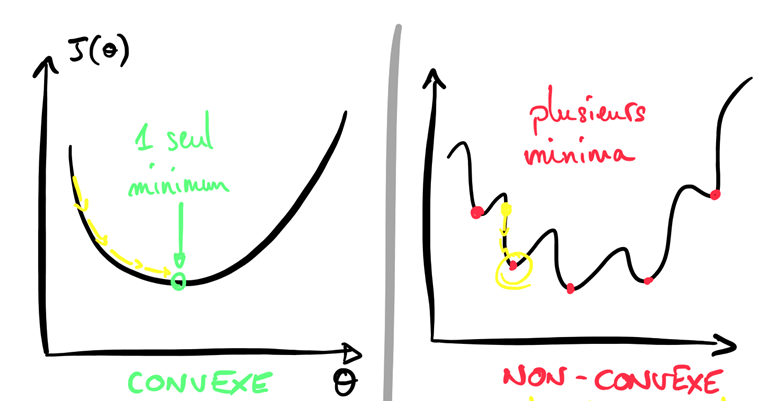
Dans le jargon, on appelle cette étape la phase d’entrainement du modèle. La machine choisit des paramètres pour le modèle, puis évalue sa performance (Fonction Coût) puis cherche des paramètres qui peuvent améliorer sa performance actuelle, etc.
Une fois la phase d’entrainement terminée vous avez un modèle de Machine Learning !
En Conclusion
Vous connaissez à présent les 4 étapes qui donnent vie à un programme d’apprentissage supervisé (Supervised Learning). La mécanique est simple et est applicable pour tout problème d’apprentissage supervisé avec un Dataset (x, y) :
- Importer le Dataset et le diviser en un vecteur y et une matrice X
- Créer un Modèle f qui produit une prédiction en fonction de certaines conditions
- Créer une Fonction Coût qui sera utilisée pour calculer la performance du modèle sur les exemples du Dataset.
- Utiliser un Algorithme d’Apprentissage pour trouver le modèle qui minimise la Fonction Coût.
Cette démarche fonctionne aussi bien pour les problèmes de régression (prédire le cours de la bourse, prédire le temps de trajet d’un taxi, etc…) que pour les problèmes de classification (détecter une cellule cancéreuse, trier des email spam, etc…) et même pour les classifications en Deep Learning (vision par ordinateur, reconnaissance vocale, etc…)


Ping : Cours de Machine Learning Python - Machine Learnia
Bonjour merci bien pour votre explication sur le machine learning . mais j’ai une préoccupation à vous soumettre.
en fait, j’aimerai savoir comment représenter un nuage de point dans le cadre d’un model de régression linéaire multiple avec python.
Merci Bien pour tout et j’espère avoir une réponse de votre part.
Bonjour Stéphane et merci beaucoup ! J’ai créé plusieurs vidéos qui répondent parfaitement à votre question. Regarder mes vidéos Sur Seaborn et matplotlib (mais je conseille surtout Seaborn)
Bonjour, Gauillaume, merci pour le travail, continue….
j’aimerais bien recevoir votre livre
Merci infiniment.
Bonjour et merci beaucoup. Le livre est en lien ci-dessus
Bonjour Guillaume
J’apprecie bcp tes video de formation et je me suis meme abonne. Je suis medecin de profession et je suis fan du machine learning. J’ai bcp apprisde la 1ere a la 21eme. Je ne trouve pas la 22eme a la 30eme sur youtube.
Merci de me fournir les videos youtube de 22 a 30.
Bonjour et merci beaucoup. C’est un plaisir de savoir qu’un médecin, passionné de machine learning peut trouver des informations utiles dans mon contenu.
Les vidéos 22 – 30 ne sont pas encore sorties, je suis en train de les produire.
A bientôt !
Merci Guillaume!
Hâte de poursuivre ma lecture!
Par contre, je crois que le lien vers ton livre https://mailchi.mp/04c8831c4940/ebook ne fonctionne pas?
Merci!
PF
Bonjour, En effet il faut désormais télécharger le livre depuis la page d’accueil, je dois corriger ce lien durant mon temps libre
bonjour Guillaume
Merci pour ces vidéos super inintéressantes. Au fait pouvez vous faire un vidéo sur le clustering s’il vous plait?
Bonjour et merci ! Une vidéo sur ce sujet va bientôt sortir 🙂
Guillaume, Bonjour avant tout j’aimerais vraiment te remercié pour tout ce que tu fais pour nous.
j’aimerai savoir si ca serai possible que tu nous fasses des vidéos sur tensorflow 2 s’il te plait
que Dieu te bénissent amen
Oui je vais en faire merci beaucoup 🙂
mais je t’en pris.
une fois encore c’est a nous de te remercie
voici un lien que j’ai trouve https://www.tensorflow.org/tutorials/keras/classification
Merci pour cet article qui est plutôt très enrichissant.
J’aimerais vous poser une question qui ne rentre dans le cadre de cet article :
Lors d’un projet de Machine Learning, quel traitement allons nous faire sur les variables qui sont corrélées dans données ?
Vous remerciant par avance pour réponse
Merci pour vos efforts considérables, Vous avez bien éxpliqué les bases et les concepts !
Bonjour Guillaume, je découvre le blog via cet article… Bravo pour cette synthèse pédagogique sur l’apprentissage supervisé ! Je trouve le sujet très bien abordé. Merci !
Merci beaucoup 🙂
Salut Gaullaume,
Merci pour tes cours avec des valeurs pédagogiques très élévées. en peu de temps j’ai compris l’apprentissage automatique.
Bravo