
Blog

Dans cet article, vous allez apprendre ce qu’est le Machine Learning, comment cela fonctionne, et pourquoi l’utilise-t-on.
Les ordinateurs ne sont pas intelligents
Un CPU (Central Processing Unit) étant majoritairement composé de transistors, les ordinateurs ne savent en réalité faire qu’une chose : des calculs.
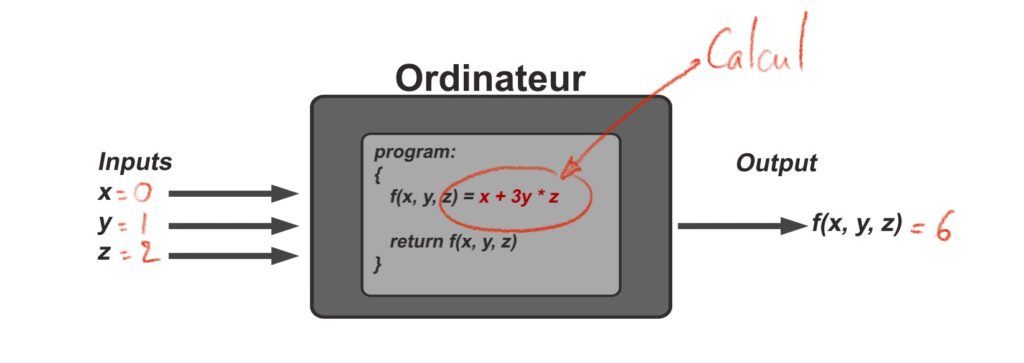
Les ordinateurs ne sont pas intelligents, il ne savent faire que des calculs.
Ce qui est amusant, c’est qu’ils peuvent ainsi effectuer en quelques secondes des calculs qui nous prendraient des milliers d’années à résoudre (envoyer une fusée dans l’espace), par contre, ils sont incapables de reconnaître un chat sur une photo. C’est parce que dans le premier cas, il suffit d’entrer des équations mathématiques bien connues dans l’ordinateur en écrivant un programme, c’est ce qu’on appelle la programmation, mais dans le second cas, il n’existe pas de calcul exact pour reconnaître un chat à partir de pixels…
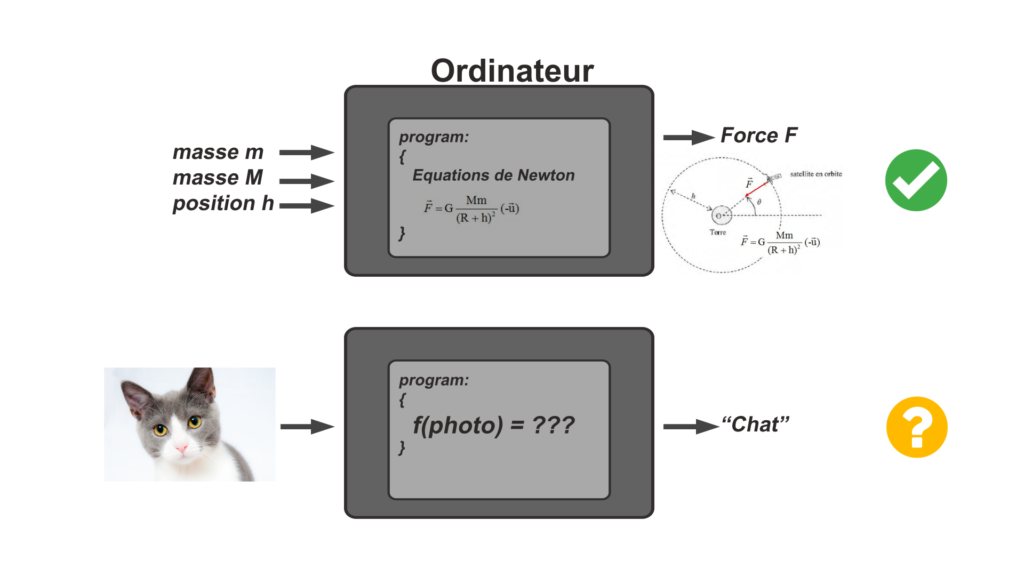
Un ordinateur ne peut faire que des calculs. Mais peut-on tout résoudre par des calculs?
D’une manière générale, peut-on décrire le fonctionnement de notre cerveau (raisonnement, mémoire, etc.) par un système d’équations ? Non. Mais il existe une solution…
L’Intelligence Artificielle, une solution ?
Face à ce problème, Alan Turing, un des pères fondateurs de l’intelligence artificielle, s’est posé une question, en 1950, dans son article scientifique Computing Machinery and Intelligence. Voici la question : « Can machines do what we do ? » autrement dit, est-ce qu’une machine peut faire ce que nous, les êtres humains, faisons ? Parce que nous, en plus de faire des calculs, et bien nous sommes capables de résoudre des problèmes, jouer aux échecs, conduire une voiture, ou bien reconnaître les objets que nous voyons tout autour de nous…
Cette question pose en réalité la base de ce qu’on appelle l’Intelligence Artificielle : Ensemble des théories et des techniques qui cherchent à développer des systèmes capables de simuler ce que les êtres humains font.
Eh bien, le Machine Learning, c’est une technique qui permet aux ordinateurs de réussir à faire tout ce genre de choses.
Machine Learning, une technique au sein de L’IA
Grâce au Machine Learning, nos ordinateurs sont capables de conduire des voitures et des avions de façon plus sûre que nous, ils peuvent diagnostiquer un patient (cancer, fracture) de façon plus fiable qu’un médecin. Le Machine Learning est aujourd’hui au cœur de nos systèmes de prise de décision : Banque, justice, sécurité, business, marketing. Les algorithmes de Google, Youtube, Facebook, Amazon, ou Netflix, fonctionnent tous grâce au Machine Learning. Avec le machine Learning, les ordinateurs peuvent même apprendre à peindre, ou composer de la musique.
Bref, on retrouve le Machine Learning partout. Mais comment cela fonctionne-t-il ?
Comment fonctionne le Machine Learning ? Définition
Le Machine Learning, ça consiste à écrire un programme qui au début ne sait rien faire, mais qui va apprendre à faire quelque chose avec le temps et l’expérience… Un peu comme un être humain apprendrait à faire du vélo : au début on y arrive pas du tout, mais à force d’en faire et bien on y arrive de mieux en mieux, jusqu’au moment où on en fait super bien.
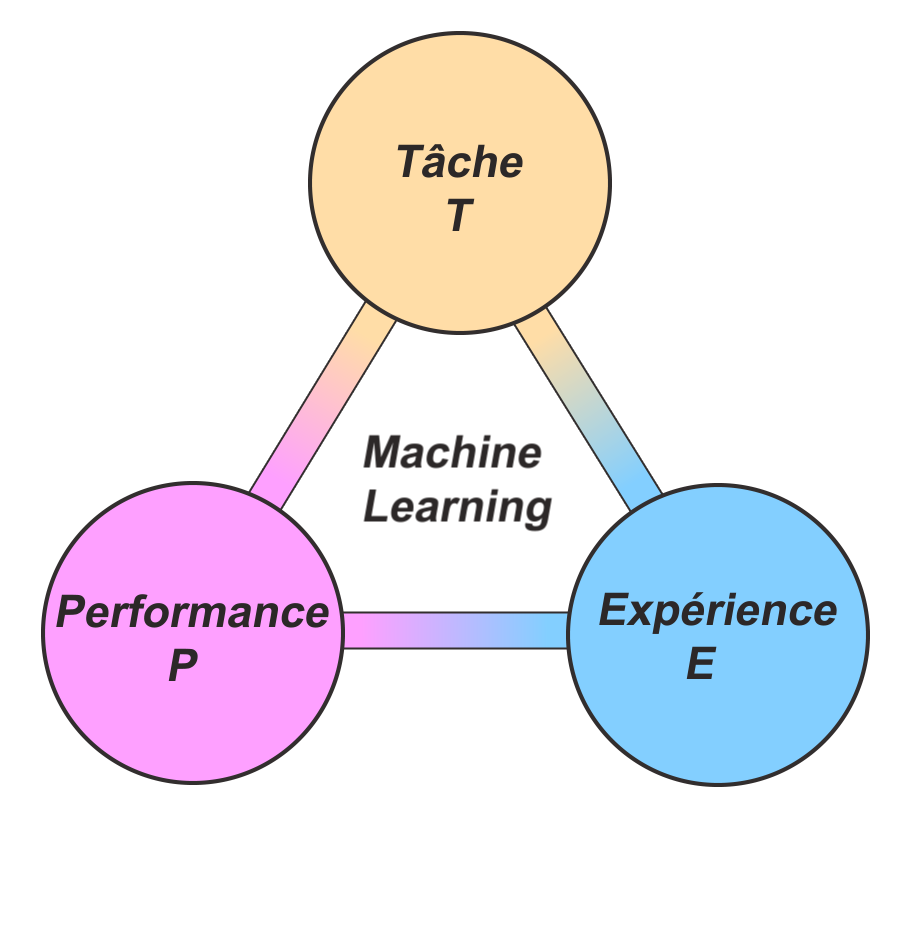
Cet exemple colle hyper bien avec la définition du Machine Learning donnée par l’américain Tom Mitchell en 1998. Selon lui, une machine apprend, lorsque sa Performance P à faire une Tâche T s’améliore grâce à une nouvelle Expérience E.
- Tâche T : Faire du vélo
- Performance P : Rouler droit, ne pas tomber
- Expérience E : chaque fois que l’on fait du vélo, y compris les fois où l’on tombe.
Mais c’est Arthur Samuel, un professeur américain, qui fut le premier à user du terme de Machine Learning pour expliquer en 1959 le fonctionnement de son programme de jeu de Dames. Il déclara: “Machine Learning is a Field of study that gives computers the ability to learn without being explicitly programmed”. Autrement dit, Le Machine Learning, c’est une discipline qui vise à donner à un ordinateur la capacité d’apprendre, plutôt que de dicter comment il doit faire les choses.
Les 3 méthodes d’apprentissage en Machine Learning
Nous reviendrons à son histoire en Bonus à la fin de cet article, car je pense que vous êtes avant tout curieux d’apprendre comment le Machine Learning fonctionne vraiment ! Parce que c’est bien beau de dire que « c’est un programme qui au début ne sait rien faire, mais avec le temps il apprend à faire des trucs bla-bla-bla » Mais justement ?! Comment écrire un programme pour donner la capacité à un ordinateur d’apprendre, sachant qu’un ordinateur ne sait faire que des calculs ?!
Eh bien il existe de nombreux algorithmes d’apprentissage, et ensemble nous allons voir les 3 familles d’algorithmes les plus utilisés, à savoir :
- Supervised Learning
- Unsupervised Learning
- Reinforcement Learning
Supervised Learning : Montrer à la machine ce qu’elle doit faire
La technique la plus répandue pour donner à un programme la capacité d’apprendre, c’est d’utiliser l’apprentissage supervisé, Supervised Learning.
La création d’un modèle
Dans cette méthode, on commence par entrer dans l’ordinateur un calcul au hasard, que l’ordinateur va résoudre pour faire sa tâche T. C’est ce qu’on appelle un modèle. Par exemple on va lui donner la tâche de déterminer le prix d’un appartement f(x) selon sa surface habitable x, et pour cela, voici le calcul à résoudre : f(x) = x.
A ce stade, selon l’ordinateur, un appartement de 100 m2 vaut 100 euros. Pas terrible comme modèle… Alors on va donner de l’expérience à la machine pour qu’elle améliore ce modèle.
L’entrainement du modèle
Pour ça, on va chercher des exemples d’appartements, beaucoup d’exemples, c’est ce qu’on appelle des données (Data). On va montrer à la machine un premier appartement, par exemple un appartement qui fait 100 m2 et l’ordinateur va utiliser son calcul : f(x) = x pour prédire une valeur de 100 euros. Et là on va lui montrer la réponse qu’il était censé nous donner, c’est pour ça qu’on parle d’apprentissage supervisé.
On lui dit : « Non non non, cet appartement que tu viens de voir, en fait il coûte 300,000 euros. ». Et là, dans le programme il y a un algorithme qui va faire 2 choses:
- Premièrement, il va mesurer l’erreur entre la réponse de l’ordinateur (100), et le résultat attendu (300,000).
- Deuxièmement, il va légèrement modifier le calcul f(x) = x qui a permis à l’ordinateur de donner cette réponse dans le but de minimiser cette erreur, c’est-à-dire améliorer sa performance P à trouver le juste prix. Par exemple, ce calcul va devenir f(x) = 3000 x
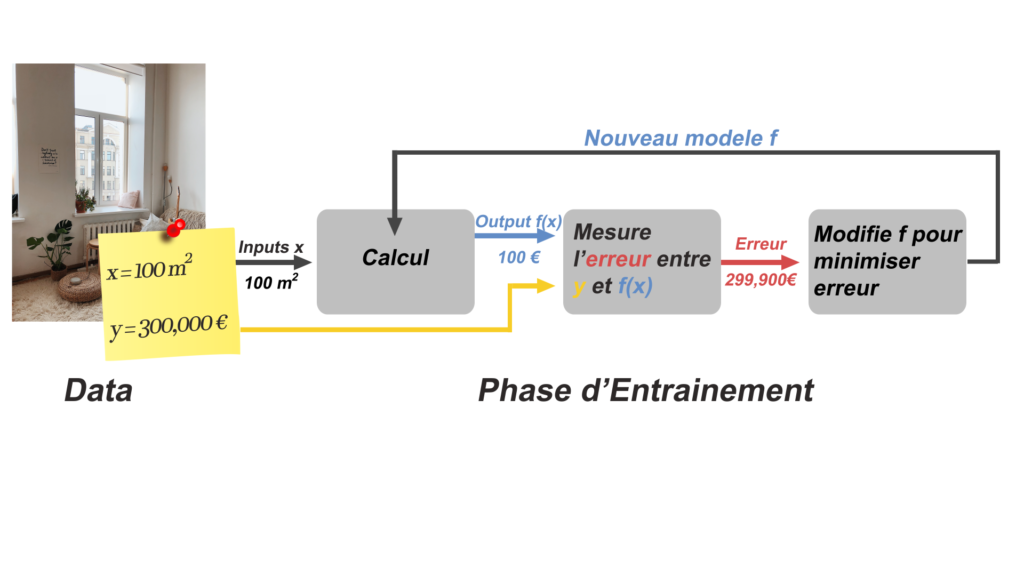
Supervised Learning: montrer à la machine les bonnes réponses
Plus l’entrainement est long, meilleure sera la performance
On va ainsi montrer une grande quantité d’exemples d’appartements, et à chaque fois le programme va procéder à son auto-évaluation, puis va légèrement corriger le calcul qu’il utilise afin de minimiser ses erreurs. Ce processus, c’est ce qu’on appelle la phase d’entraînement. Selon le nombre d’exemple dont on dispose, et la complexité de la fonction à apprendre, cette phase peut durer quelques secondes, tout comme elle peut prendre plusieurs années.
Applications du Supervised Learning
Le Supervised Learning est le type de Machine Learning le plus répandu, parce qu’il existe un nombre immense d’applications dans lesquelles nous avons à disposition des exemples (des data) sur lesquels on peut mettre une étiquette (associer un appartement à un prix, dire ce qu’une photo représente). On compte en général 2 familles de problèmes
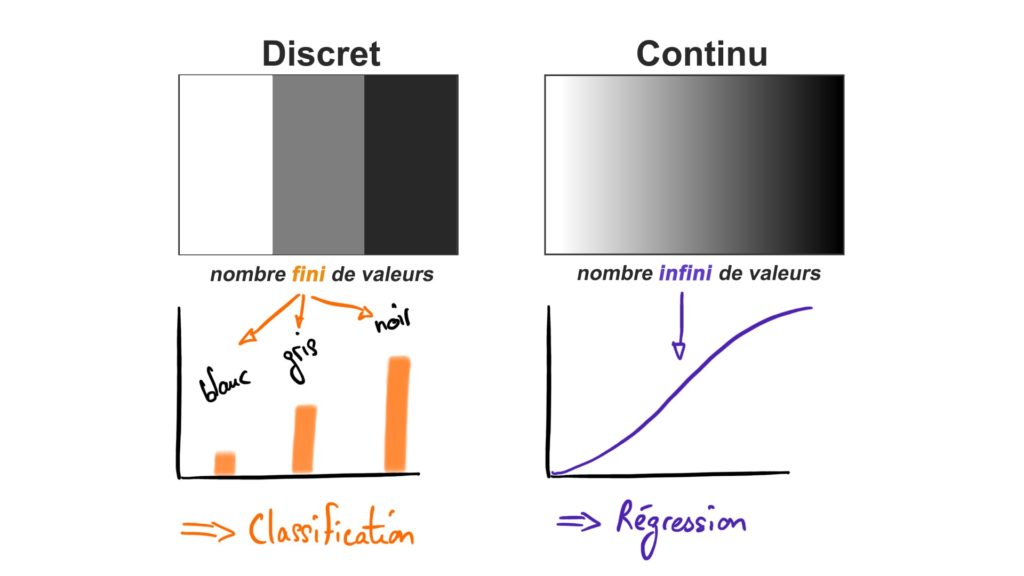
- Les problèmes de régression, qui consiste à prédire la valeur d’une variable continue :
- Prix de l’immobilier
- Valeur d’une action boursière
- Température qu’il fera demain ou dans 10 ans
- Somme du panier achat client
- Consommation électrique d’une usine
- Position du bras d’un robot en automatique
- Les problèmes de Classification, qui consiste à prédire la valeur d’une variable discrète :
- Est-ce que l’email est un spam ?
- Est-ce-que ce logiciel est un malware ?
- Est-ce que la radio montre une fracture ?
- Est-ce que les analyses médicales montrent un cancer ?
- Quel animal est sur la photo ? Chien ? Chat ? Renard ?
Algorithmes de Supervised Learning
Les algorithmes de Supervised Learning pour réussir à faire ce genre choses sont légions : K-Nearest Neighbour, Régression Linéaire, Régression Logistique, Support Vector Machine, Neural Network, Naive Bayes, Random Forest, Adaboost, etc.
Voilà pour le Supervised Learning. Mais saurez-vous devinez quelle autre stratégie peut être mise en place pour donner à un ordinateur la capacité d’apprendre ? La réponse tout de suite…
Unsupervised Learning : Laisser la machine apprendre toute seule.
La deuxième technique pour donner à un programme la capacité d’apprendre, c’est d’utiliser l’apprentissage non supervisé : Unsupervised Learning. Mais quelle est la différence avec la première méthode ?
Eh bien vu qu’on ne supervise pas l’apprentissage, c’est-à-dire qu’on ne montre pas à la machine des exemples de ce qu’elle est censée nous donner comme résultats, le programme qui auparavant procédait à son auto-évaluation, ne sait plus quoi faire car il ne peut pas comparer ses résultats avec des exemples.
Eh oui ! Cette fois-ci au lieu de dire « voici une photo de chat, une photo de chien, etc. », on lui dit : « voici pleins de photos, débrouille toi ». Ce à quoi la machine pourrait nous répondre : « Bon ok je me débrouille, mais…qu’est-ce que tu veux que j’apprenne ? »

S’il n’y a pas d’exemples a copier, que faut-il apprendre ?
En fait, dans le Unsupervised Learning, on demande à notre programme d’apprendre à reconnaître des structures dans ce qu’on lui montre. Des ressemblances. Des différences. Et avec la connaissance que le programme va développer sur ces structures, on va pouvoir l’utiliser pour faire pleins de choses comme regrouper ses exemples selon leurs points communs.
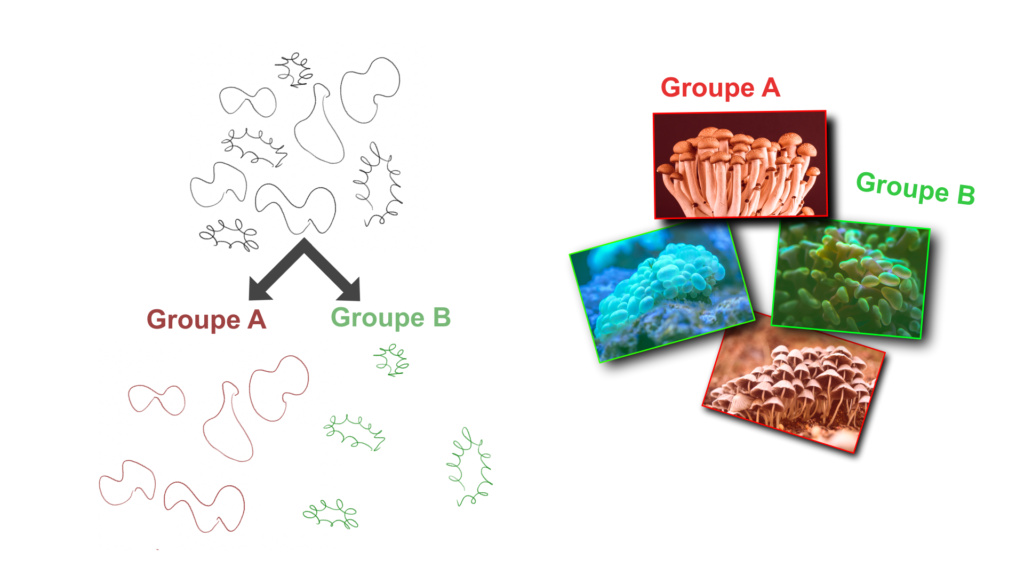
Par exemple si je vous montre les images suivantes en vous demandant de les regrouper en deux groupes, vous allez probablement faire comme ci-dessous, et ceci sans avoir besoin de savoir à quoi ces images correspondent.
Applications du Unsupervised Learning
Eh bien faire ce genre de chose, par exemple avec le K-mean clustering, c’est utile pour faire des études de marché, du business, du merchandising (rassembler ensemble les produits qu’un client est susceptible d’acheter).
On va se servir de la connaissance qu’un programme aura accumulé en analysant la structure de données qu’on lui donne pour la recherche scientifique, la recherche médicale (classer de nouvelles maladies, nouvelles bactéries) pour étudier le comportement des animaux, décrypter des langues anciennes, ou encore la réduction de dimensions. Une autre application très courante est le développement de systèmes de détections d’anomalies (fraudes bancaires, piratage internet, caméra de surveillance).
En général, si nous disposons de données étiquetées, on opte pour le Supervised Learning, et on utilise le Unsupervised Learning dans les cas où les données sont mal comprises voire inconnues (par exemple la recherche médicale).
Algorithmes de Unsupervised Learning
Les algorithmes les plus utilisés en Unsupervised Learning sont : K-mean Clustering, Anomaly Detection Systems, Principal Component Analysis, Auto-encoder Neural Networks, Generative Adversarial Network, Manifold Learning, etc.
Bon, nous venons de voir 2 familles d’algorithmes d’apprentissage. Faisons une pause. Vous aimez les animaux ? Peut-être avez-vous un chat ou un chien ? Vous est-il arrivé de donner à votre animal une friandise pour leur apprendre à donner la papatte ? Bingo ! C’est ce qu’on appelle l’apprentissage par renforcement. Voyons ça tout de suite !
Reinforcement Learning: Laisser la Machine générer sa propre expérience
La troisième famille d’algorithmes d’apprentissage est celle que j’affectionne le plus pour sa complexité et ses applications. Il s’agit de l’Apprentissage par Renforcement, ou Reinforcement Learning. Peu de gens connaissent ce terme, pourtant c’est cette discipline qui s’approche le plus de l’idée de ‘robot intelligent’ capable de faire ce que nous faisons: conduire une voiture, résoudre des problèmes, jouer aux échecs, etc.
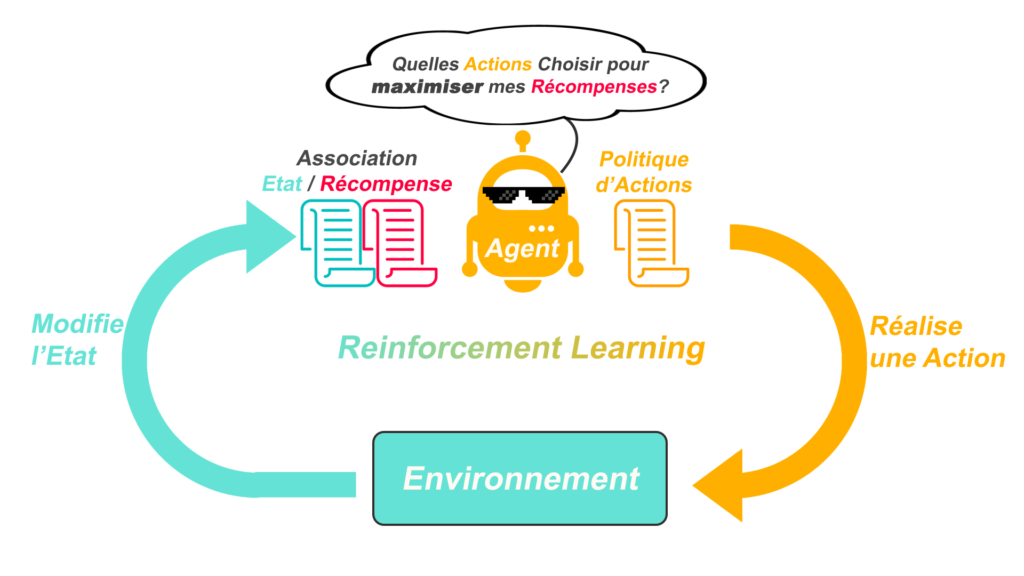
Dans cette technique, la machine génère elle-même ses propres expériences. Sous forme d’Agent, elle a la liberté d’entreprendre des Actions au sein d’un Environnement. Suivant l’action entreprise, l’Environnement modifie l’État de l’Agent et donne une récompense positive ou négative associée à cet État. Ceci constitue une nouvelle expérience.
Au sein du programme, il y a un algorithme qui développe une politique d’actions dans le but de maximiser le nombre de récompenses positives, c’est-à-dire améliorer la performance P.
Exemple pour illustrer l’apprentissage par renforcement
Imaginons que notre Agent soit une voiture. A chaque instant, la voiture peut choisir d’entreprendre des actions dans son Environnement qui est la route : elle peut freiner, accélérer, tourner à gauche, ou tourner à droite. Si l’Agent choisi de tourner à gauche alors qu’il s’y trouve un mur, L’État de la voiture va passer de ‘Normal‘ à ‘Accidenté‘, et l’Environnement va donner à l’Agent une récompense négative. Ainsi l’algorithme qui cherche à maximiser les récompenses va modifier sa politique d’action pour ne plus refaire un tel ‘accident’.
Le programme apprend à conduire : il améliore sa performance P à ne pas faire d’accident grâce à une nouvelle expérience E.
Applications du Reinforcement Learning
Vous l’aurez deviné, on utilise le Reinforcement Learning pour développer les voitures autonomes, les drones, la robotique, mais s’est aussi grâce à ce type de Machine Learning que Deep Mind ont élaboré AlphaGo et AlphaZero pour jouer au Go. Par extension on peut utiliser le Reinforcement Learning pour tout type de jeux, y compris les jeux vidéo et pour résoudre des problèmes.
Algorithmes de Reinforcement Learning
Les algorithmes populaires du Reinforcement Learning sont la recherche de Monte Carlo, Temporal Difference Learning, SARSA, et le Q-Learning.
Ce que vous devez retenir du Machine Learning
Félicitations d’avoir lu cet article ! Je vous propose un petit résumé de ce qu’on a vu.
À la base, un ordinateur ne sait faire qu’une seule chose, des calculs, ce qui est bien différent de ce que nous savons faire : résoudre des problèmes, faire du vélo, reconnaître les objets que nous voyons autour de nous, etc.
Ainsi, l’intelligence artificielle représente l’ensemble des techniques qui cherchent à élaborer des systèmes capables de simuler ce que les êtres humains font. Parmi ces techniques, on trouve le Machine Learning, qui fonctionne tellement bien qu’il a envahi notre quotidien.
Le machine Learning consiste à écrire un programme qui apprend à faire une Tâche T lorsque sa Performance P s’améliore avec une Expérience E. Pour se faire, on utilise couramment des algorithmes de Supervised Learning, Unsupervised Learning, ou Reinforcement Learning.
Le Deep Learning, c’est du Machine Learning a grande échelle
D’une manière générale, plus on fournit d’expérience (c’est-à-dire de données) à une machine, meilleure sera sa performance. Ainsi, le Deep Learning, qui est une discipline au sein même du Machine Learning, cherche à entraîner des modèles extrêmement complexes avec des milliards de données dans le but de surpasser les performances humaines.
Le Machine Learning et Le Deep Learning sont aujourd’hui des domaines en plein envol, ceci grâce à l’émergence des objets connectés en 2007 (lancement de l’IPhone) qui ont fournissent aujourd’hui une avalanche de données (Big Data) pour entraîner les modèles des Data Scientists.
À vous de jouer!
Si vous avez pour objectif de devenir un expert en Machine Learning, Deep Learning ou Data Science, c’est le moment de vous lancer ! Vous êtes libre de recevoir gratuitement des codes et des formations exclusives par email chaque semaine, il suffit de vous inscrire ici.
16 commentaires
Les commentaires sont clos.
Une bonne introduction pour un néophyte total !
Merci Alex !
Cet article a vraiment été écrit pour les néophytes, donc je suis ravi de savoir qu’il a pu vous aider.
Toute question est la bienvenue !
très bon article.
dès maintenant je vous suivre
merci
Un grand merci ! N’hésitez pas à me poser vos questions ! A bientôt.
Voila une bonne intro. merci
Merci beaucoup. Si vous voulez allez plus loin que l’intro, je vous conseille les tutoriels du site et sur ma chaine YouTube.
Bonjour Mr Guillaume je m’appelle Hertzy je suis un congolais je suis un coders je fais le génie logiciel.je code en python et en java. Je veux me lancer dans IA j’ai lue votre livre et il est très instructif mais je n’arrive toujours pas a me sentir près pour prendre ce chemin de l’IA quel conseil je pourrais avoir de vous ?
Puis il ya tellement des fonctions que vous utilisez dans votre livre on sais pas comment nous retrouver je pourrais avoir des éclaircissements ?
Bonjour et merci beaucoup Hertzy. Je vous conseille de suivre ma formation gratuite sur YouTube. Elle aborde les fonctions étape par étape et vous aidera aussi bien qu’elle a déjà aidé tous les gens qui l’on regardé !
Bon courage et je vous soutiendrai !
Excellente introduction.
Bravo
bonjour
j’ai commencé à explorer vos vidéos sur le machine learning et python
C’est du très beau travail et je vous remercie de les mettre ainsi en ligne
Concernant celles sur python, je voudrai savoir si les scripts que vous écrivez sont disponibles en téléchargement
merci de votre réponse
Merci beaucoup ! Je vais mettre les script en lignes quand j’aurais un peu plus de temps libre !
Bonjour Guillaume;
Chose que je n’arrive pas à comprendre dans l’apprentissage supervisé par un modèle KNN c’est:
Que dans un modèle de regression linéaire ou polynomiale on cherche à optimiser l’erreur pour trouver les meilleurs parametres et ce en commencant par des parametres arbitraires pour le modèle choisi, c’est ok. Mais dans les knn, comment choisir mon modele? ou juste annoter les sorties de mes features? ou quoi faire vraiment c le point que je n’arrive pas à comprendre et j’aimerais bien comprendre ça.
Merci beaucoup pour cette série de cours en ML.
Très clair comme présentation. Bravo, il y a vraiment peut de spécialistes capables d’expliquer simplement ces choses.
Salut Guillaume, j ai découvert votre chaîne YouTube par le biais d’un ami et je suis à ce jour plus fan de vous que lui. Je vous remercie beaucoup pour la qualité du travail abattu et je vous encourage à aller plus loin. Merci beaucoup.
Salut Guilaume, je vous remercie beaucoup pour ce travail incontournable.
Merci beaucoup pour ce post.